How I built WordLink
I’m excited to announce that my new website WordLink search is now live and accepting visitors. I have been working on this personal project since January 2022, when I started developing a prototype search program in Python. This blogpost gives a chronological account of the site’s development, together with an overview of some of the notable challenges I had while building it.
The idea
I came up with the idea for the website while learning some Italian a few years ago. When learning vocabulary, I found that words which were similar in Italian and English were much easier to learn than words that weren’t (unsurprisingly). But for many words that initially seemed disimilar, I was able find a ‘linking’ word, and that made it much easier to learn.
For example, the Italian word temere, meaning to fear, is very similar to timid. This is not a coincidence. The English timid and Italian temere both have the same root in Latin, so it makes sense that they use similar letters and have a similar meaning. Every time I struggled with learning a new word in Italian, I invested some time searching through the etymology sections of different dictionary websites trying to find these linking words, and every time I found it useful.
One of my favourite discoveries was the link for oltre, which is Italian for further. It turns out that the English word outrage actually comes from the Latin ultra (meaning beyond), and over the past 2000 years has evolved to ultraticum (Vulgar Latin for a going beyond), to oultrage (Old French for excess), and finally to outrage in English. While the word outrage looks like out+rage, neither out nor rage is etymologically related it!
Prototype
The first thing I did was to develop a prototype to prove that it was possible to programmatically find these linked words. The algorithm I was following myself was to follow links from the etymology section of Wiktionary until I’d found a satisfactory link. I downloaded the English Wiktionary using the same method as my Spanish gender semantics project, and modified the Python code to look for etymology links within the pages.
Wiktionary has a few ways to record these etymology links, but the main one is with templates. For example, let’s look at Wiktionary’s etymology section for outrage.
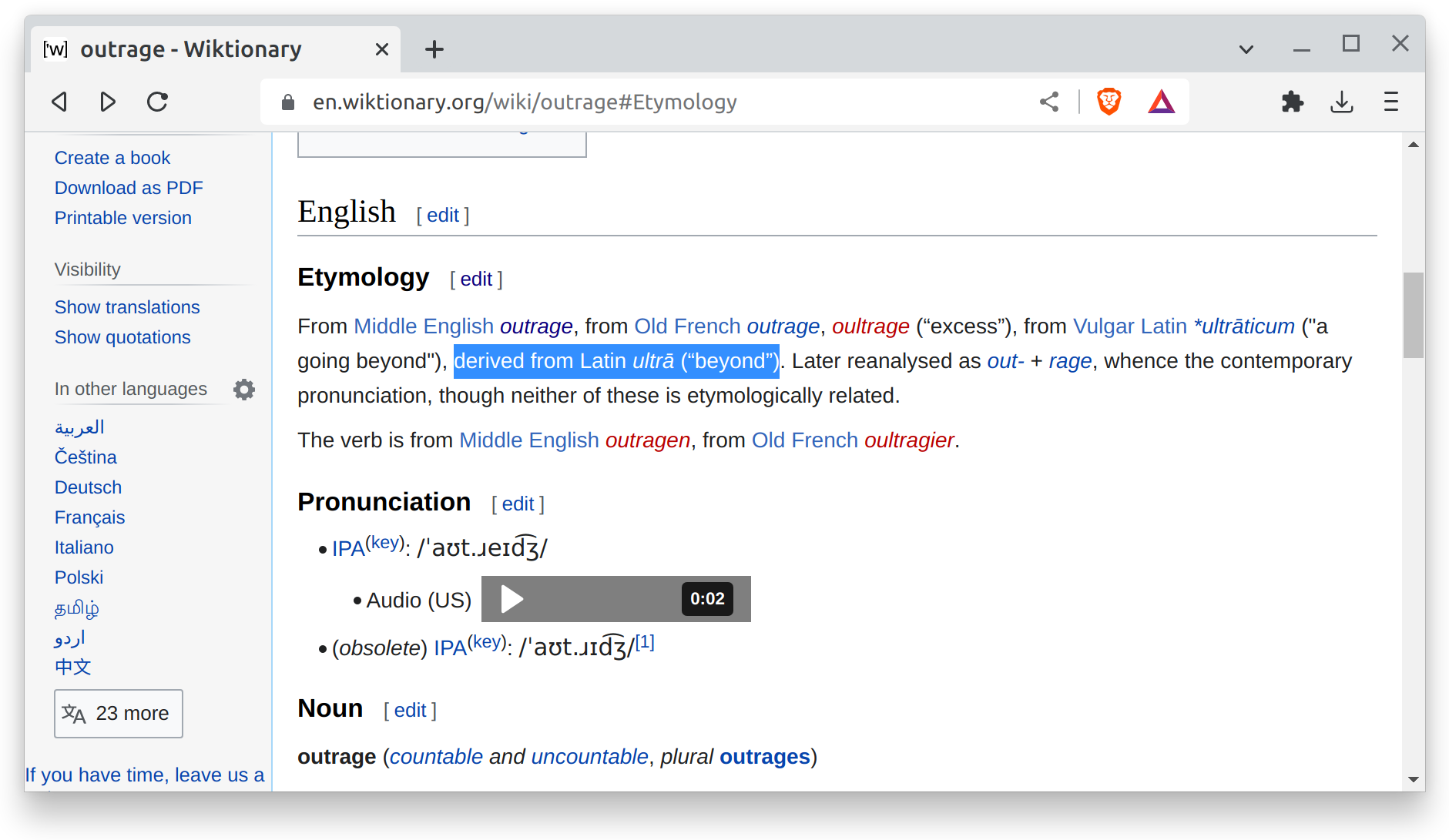
The section reads derived from Latin ultrā (“beyond”), but actually in the raw wiki markup file, it’s written like this: {{der|en|la|ultrā||beyond}}. This template says the English (en) word outrage is derived (der) from the Latin (la) word ultrā, and that ultrā means beyond.
For our purposes, we can extract this etymology link by searching for the der templates, and record the link between the words.
Having extracted these links between words, we can then chain the links together. My first successful search linked the English word ultra to the Italian word oltre.
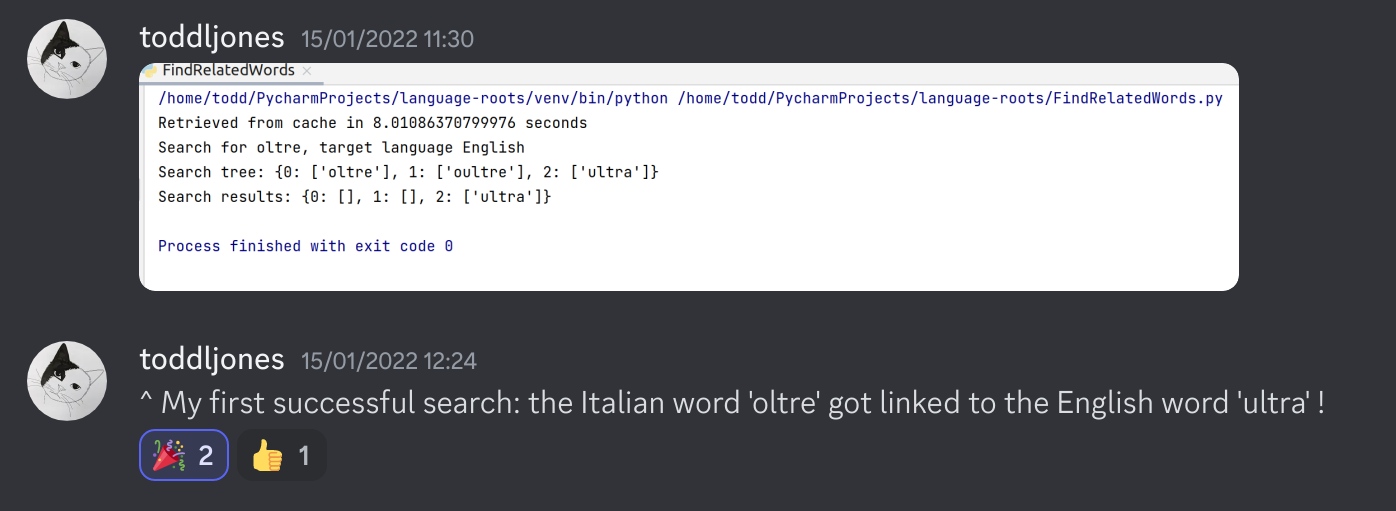
There were a few more links that I found using the Python prototype.
This showed that the idea was feasible, but it also gave me an insight into one of the challenges I’d face with the project.
Wiktionary pages are written by many individual contributors, and they’re not always consistent.
Many etymology sections just use hyperlinks, rather than the der template above, for example.
Backend server and API
The next milestone was developing a backend server application that could extract these links from Wiktionary and perform a basic search.
I wanted to use the project to learn about tools which I’d had limited exposure to previously, so I created the server application using the following:
- Springboot: This is the Java framework that creates the backend server application. I just annotate my Java classes to get them installed in the server.
- Gradle: I used this Java build tool to record my Java dependencies, build the code and run automated tests.
- Docker: I created a docker image for my server application to ensure my code runs in a container with a predictable environment. This makes software deployment and testing much more reliable because you no longer depend on what else is installed on the machine. Instead, you write a Dockerfile which explicitly states what is installed.
- neo4j: I used this graph database to store the links between words. Neo4j has a free tier and a premium tier. The free tier turned out to not be suitable and I replaced it with PostgreSQL later.
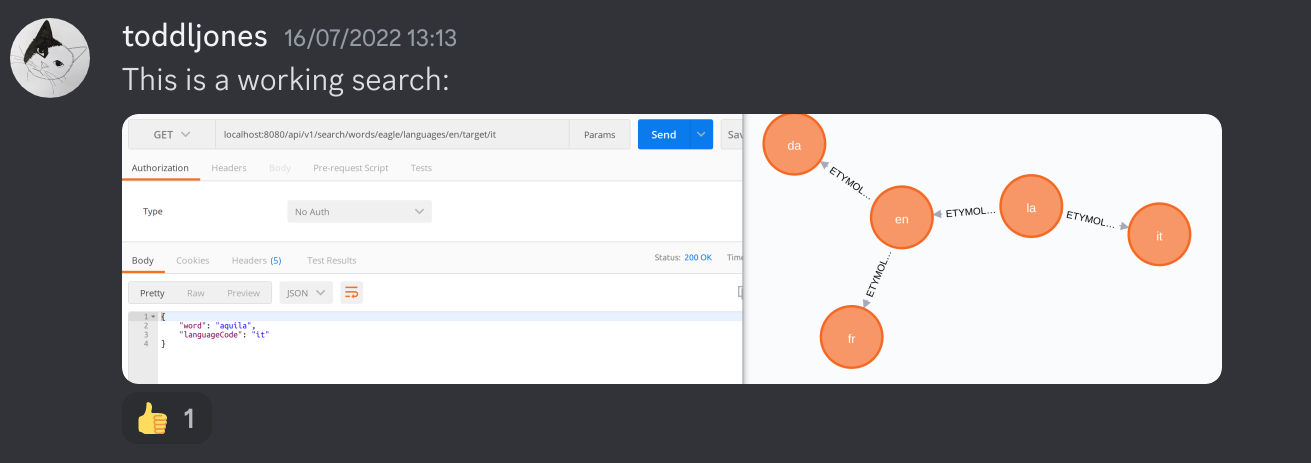
With these tools, I was able to create a basic API to search for words. This is a screenshot of a working search from the English word eagle to the Italian word aquila (meaning eagle). The diagram shows the graph of words we’re navigating in neo4j’s browser. Each node of the graph is a word in a language, but only the language is shown in the middle of the node for “reasons”.
Frontend
The next part I worked on was the website frontend. I wanted to use this as an opportunity to explore react, one of the main frameworks used to build modern websites. As such, I used the following tools:
- React: A Javascript library to build interfaces using components.
- React-query: A Javascript library to make HTTP requests and cache the responses.
After a bit of work, I arrived at a functional, but extremely ugly website.
AWS Deployment
The next problem was deploying the site into a production website. I knew I needed the following components:
- A database to store the links I’ve extracted.
- A Java application to serve search requests.
- A web server for my react frontend.
- A storage space to cache the large wiktionary data dump file while I’m extracting links from it.
I also knew that I shouldn’t rely on me remembering which buttons I’ve pressed in AWS because I’d be sure to forget. To solve this problem, I used Terraform. Terraform files encode all of the AWS components that your deployment needs, together with all of the settings. In your continuous deployment pipeline, you run a terraform server (I’m using Terraform Cloud) that records which components and settings have already been created/set. Each time you modify the Terraform files, this server compares your current AWS deployment to the new files and creates the new resources.
For the mostpart, Terraform works quite well. It tries to order the creation, modification and destruction of components correctly so it’s not creating something before its dependencies have been created. There were parts of the deployment that didn’t do this well though when destroying components, so I had to manually destroy some things in the AWS console.
Eventually I had a setup with:
- Neo4j database running in an EC2 instance with a special Neo4j AMI.
- AWS Fargate running my docker images for the Java application and the web server.
- AWS Elastic File Storage to store the data dumps when needed.
- AWS load balancers to ensure we’re pointing the website at the latest docker images.
This setup seemed to be working, however I was running into two problems:
- The AWS load balancers were too expensive.
- Searches took super long.
Major problem 1: expensive AWS load balancers
In reality, it’s more that they’re overpowered for my small website. Load balances divide a lot of internet traffic between multiple running copies of your production code. For my website that won’t have enough load to warrant multiple running copies, they’re not really necessary.
I changed my setup to remove the load balancers. Instead, the docker images now run in EC2 instances, and the EC2 instances have an elastic IP address (i.e. a fixed public IP address). Whenever I update one of my docker images, I launch a new EC2 instance and move the corresponding IP address to point at the new instance. The IP address is switched across with a AWS Lambda Function using ec2-elastic-ip-manager.
The shortcoming of this approach is that the IP address is moved to the new EC2 instance before the new instance is ready. This means there is a couple of minutes of downtime whenever I modify my code.
I think the better solution will be to run Kubernetes on the EC2 instance, and switch to the new docker image within the same EC2 instance. I’ll probably give this a go at some point in the future.
Major problem 2: Awful search performance
Now that I had a working solution in the cloud, I was able to try using my code on the full Wiktionary data dump. Up to this point, I’d only been extracting data from the first few thousand Wiktionary pages, but there are actually 7.5 million pages. The extraction got slower and slower, and I stopped the first of two extraction jobs when it had taken 30 hours to extract 1/8 of the dump.
Not only was the extraction performance poor, but the search was now really slow too. There are two API endpoints that call the database, an autocomplete endpoint that’s used in the search box, and the main search endpoint. The autocomplete took around 3 seconds and the search took about 8 seconds.
When I found out why this was happening, I was dumbfounded. I was using the free tier of the neo4j graph database, and it doesn’t come with an index on the primary key!
Let me explain what that means. Imagine you had a list of 1 million words (as my poor website did at this time), and I asked you to find the English word ‘prawn’ in the list. The inefficient way to do this is to read every word, and check whether it’s ‘prawn’. You’d have to read 1 million words in the worst possible case.
The much better solution is to sort the words (this is called using an ‘index’). You then look at the word in the middle of your sorted list. Depending on whether this middle word is before or after ‘prawn’, you discard the first or second half of the words from your search, and repeat. This way, you’d only have to check 20 words in the worst possible case. This is a very significant difference.
Once I’d confirmed that neo4j did not support adding an index in the free tier, I immediately resolved to stop using it. I changed my setup to use a PostgreSQL database, and use Amazon RDS in the deployment.
Improving the search algorithm
Once the deployment problems had been addressed, I could once again try a full extraction of the Wiktionary data dump. This time, it worked. I had to make a few performance improvements to the extraction, but it now took less than a day to do a full extraction.
I could also do some searches with the website, but these exposed some shortcomings of the algorithm I had written. For example, your search results would almost always look like ‘jump’, ‘jumps’, ‘jumped’, ‘jumper’, jumpable’, ‘jumpers’. Clearly, there are loads of redundant results there. I used the etymology links between words of the same language to filter out these unwanted results and made a few other tweaks.
Branding and styling
During the deployment to AWS, I was also tweaking the frontend to make it cleaner. I came up with ‘WordLink’ as the name for the site, and bought the domain www.wordlink.dev. I also designed and created the logo, which combines a ‘W’ with a graph linking together two words.
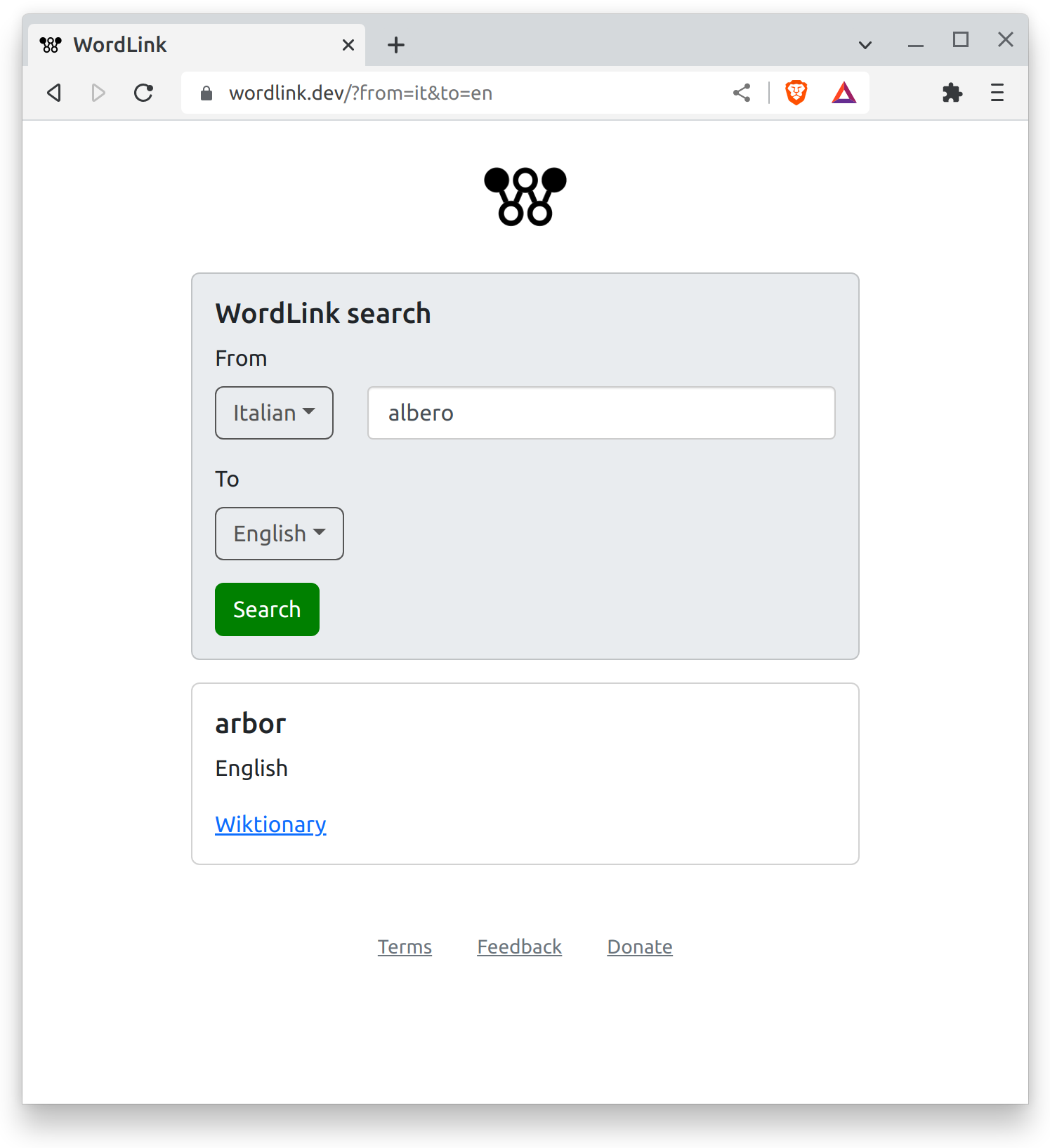
Early user testing
I invited a few people to try using the site, now that it could actually produce results. There were many pain points I had not anticipated, mainly to do with text entry on the site. iOS automatically adds a space after words, and android capitalises words. I added server-side validation to remove extra spaces and change every letter to lower case.
I also added a site description (which ChatGPT might have helped me write!).
Launch
That’s where I’ve got to so far. Please give it a go and send any feedback my way. If you want to chat more about how I built the site, please get in touch.